Research
During my PhD, I have actively engaged in a productive collaboration with the financial industry, working closely with financial institutions, banks, and public organizations. This collaboration has enabled me to deepen my practical understanding of real-world challenges in financial mathematics and contribute to solving complex problems with innovative and efficient solutions. Thanks to this particularity of my PhD program (French CIFRE PhD program), I have worked on various topics in quantitative finance, including but not limited to:
- XVA Calculation: I have collaborated with experienced professionals to enhance and accelerate XVA valuations on portfolios of various derivatives, including currency swaps, interest rate swaps, callable derivatives, CMS swaps, and more. The initial objective was to perform a comparative analysis of different XVA calculation methods, specifically sensitivities, full-revaluation using Monte Carlo, and American Monte Carlo simulations. This analysis focused on both computational efficiency and the accuracy of calculations. The second objective was to optimize the overall XVA calculation process. This involved various coding and computational improvements, as well as an in-depth analysis to determine the most effective methods for computing EEPE.
- Market Risk Measurement: I have collaborated with an international institution to measure market risk on a portfolio comprising both derivatives and securities. This project was carried out in two main phases. The first phase involved modeling all indicators that influence the valuation of products within the portfolio, such as interest rates, exchange rates, credit spreads, and more. This phase required utilizing existing models for calibration, implementation, and back-testing, as well as developing new approaches that contributed to research publications (e.g., the credit spread article mentioned below). The second phase entailed the full re-valuation of the different products through Monte Carlo simulations of the scenarios generated from the models in the first phase, followed by the calculation of various risk indicators, such as VaR and ESF, across different time horizons.
- Stress Scenario Analysis: The issue of stress testing has been a recurring theme across many projects. In interactions with practitioners in areas such as market risk, credit risk, and even counterparty risk, the need for effective stress testing solutions often arose. The objective is generally to assess the impact of specific events on valuation or solvency. This work has included, for instance, translating the effects of commodity price fluctuations on the solvency of credit portfolios, analyzing how interest rate forecasts impact portfolio valuations, and evaluating the influence of rising CDS values on CVA. Some of my contributions in stress testing have been included in research publications (see the real-world article mentioned below).
In addition to the work described above, which has contributed to addressing real-world challenges, my research has led to articles that have been submitted for publication. Below, you will find their abstracts and links to the open-access preprints.
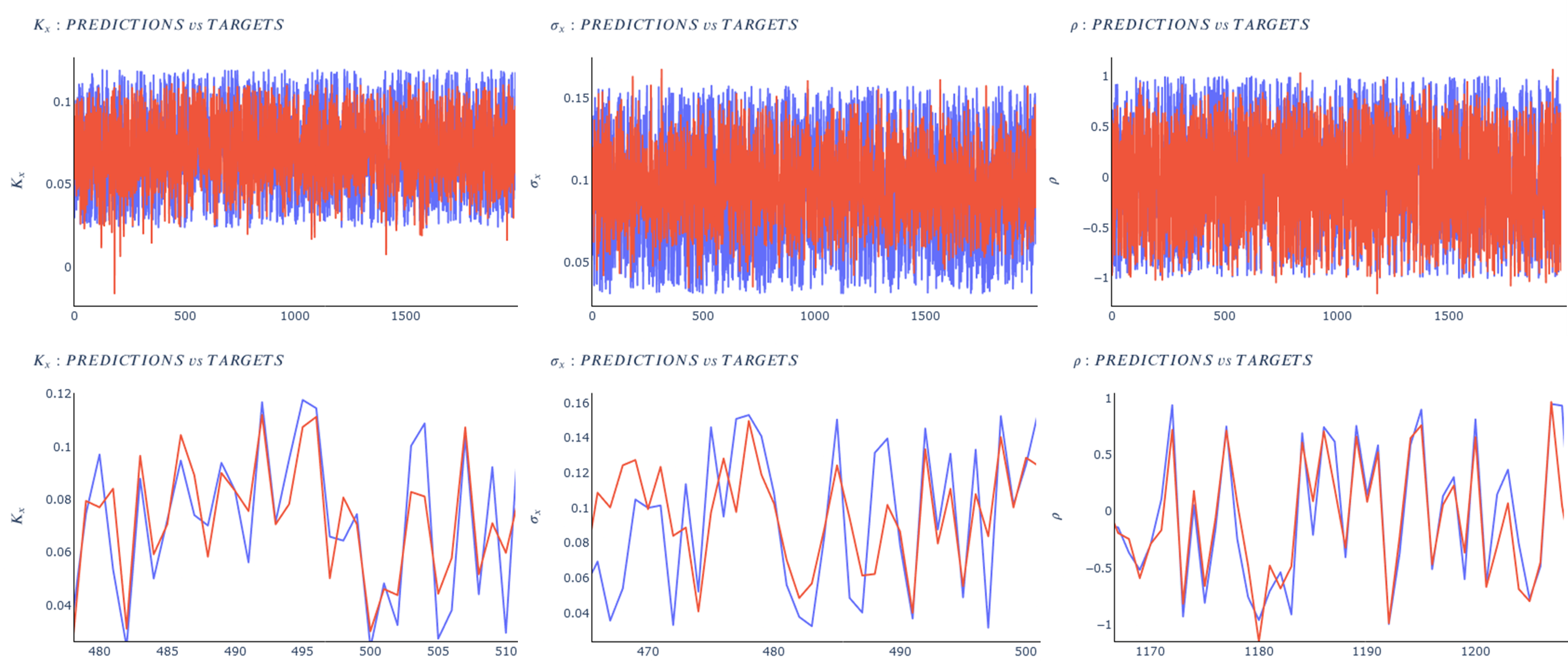
This figure compares some of the G2++ model parameters calibrated using our deep learning approach against the actual parameters (the second row is a zoomed-in version of the graphic in the first row).
Deep Calibration of Interest Rates Model
Abstract: For any financial institution it is a necessity to be able to apprehend the behavior of interest rates. Despite the use of Deep Learning that is growing very fastly, due to many reasons (expertise, ease of use, ...) classic rates models such as CIR, or the Gaussian family are still being used widely. We propose to calibrate the five parameters of the G2++ model using Neural Networks. To achieve that, we construct synthetic data sets of parameters drawn uniformly from a reference set of parameters calibrated from the market. From those parameters, we compute Zero-Coupon and Forward rates and their covariances and correlations. Our first model is a Fully Connected Neural network and uses only covariances and correlations. We show that covariances are more suited to the problem than correlations. The second model is a Convolutional Neural Network using only Zero-Coupon rates with no transformation. The methods we propose perform very quickly (less than 0.3 seconds for 2,000 calibrations) and have low errors and good fitting.
Mohamed Ben Alaya, Ahmed Kebaier, Djibril Sarr, 2021. (Preprint available here. A first version of this work was published in the 2022 annual proceedings of the SFdS, Société Française de Statistique, pages 906-911.)
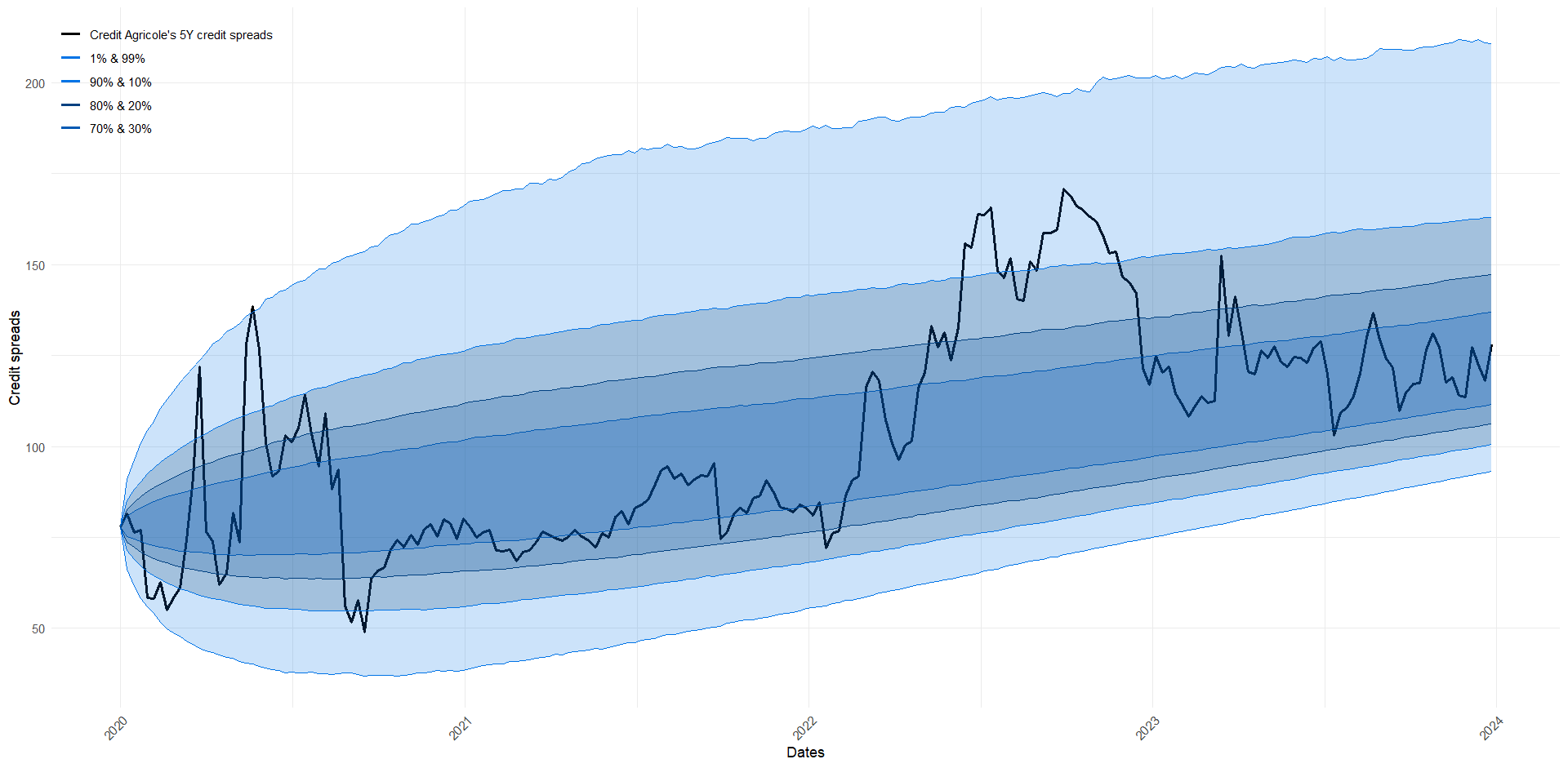
This figure shows the back-testing of the model, highlighting how the simulated credit spreads (shades of blue) closely follow and encompass the actual credit spread curve (black line) over time.
Credit Spreads' Term Structure: Stochastic Modeling with CIR++ Intensity
Abstract: This paper introduces a novel stochastic model for credit spreads. The stochastic approach leverages the diffusion of default intensities via a CIR++ model and is formulated within a risk-neutral probability space. Our research primarily addresses two gaps in the literature. The first is the lack of credit spread models founded on a stochastic basis that enables continuous modeling, as many existing models rely on factorial assumptions. The second is the limited availability of models that directly yield a term structure of credit spreads. An intermediate result of our model is the provision of a term structure for the prices of defaultable bonds. We present the model alongside an innovative, practical, and conservative calibration approach that minimizes the error between historical and theoretical volatilities of default intensities. We demonstrate the robustness of both the model and its calibration process by comparing its behavior to historical credit spread values. Our findings indicate that the model not only produces realistic credit spread term structure curves but also exhibits consistent diffusion over time. Additionally, the model accurately fits the initial term structure of implied survival probabilities and provides an analytical expression for the credit spread of any given maturity at any future time.
Mohamed Ben Alaya, Ahmed Kebaier, Djibril Sarr, 2024. (Preprint available here.)
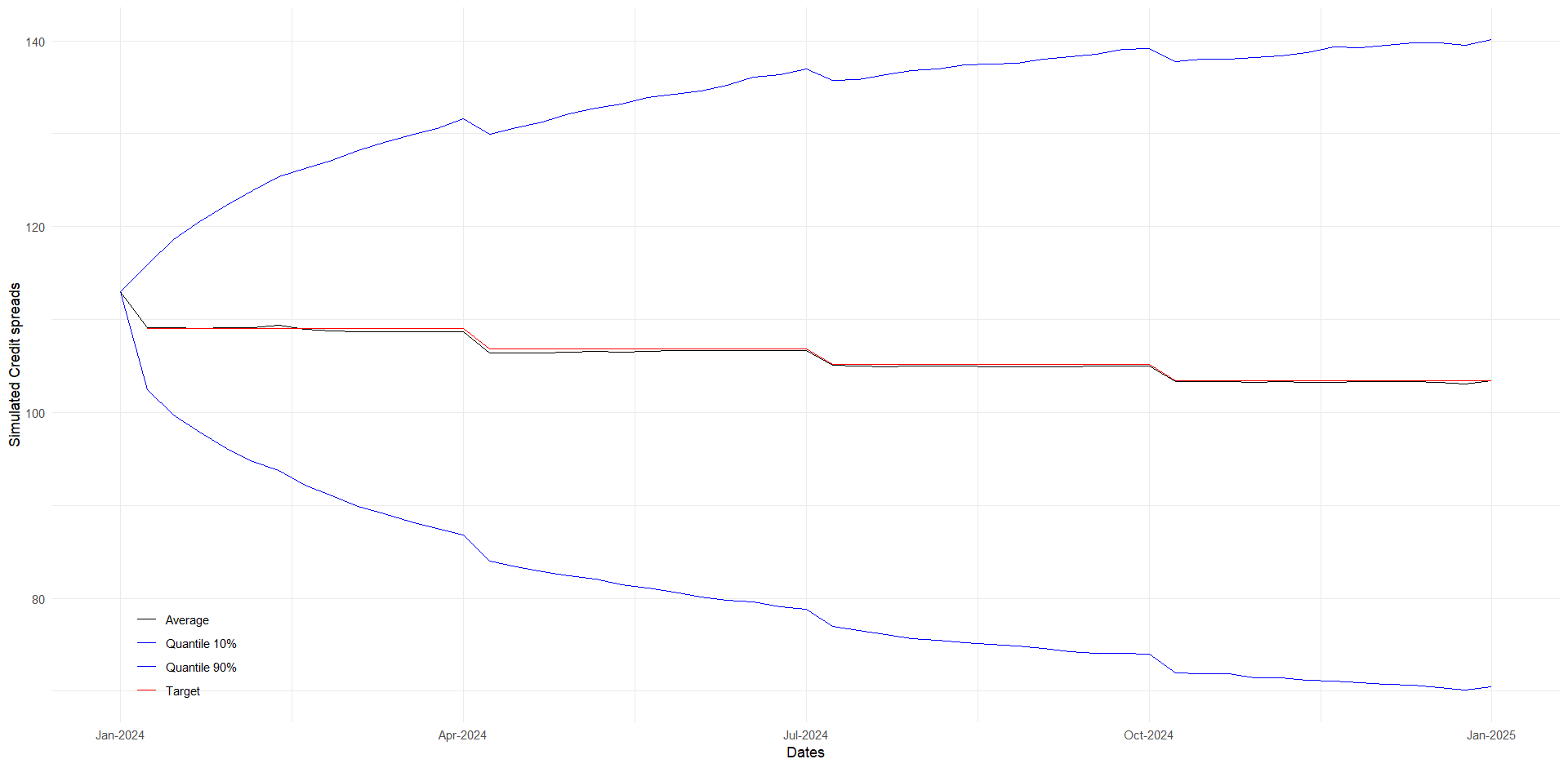
This figure shows how the expectation of the Real-World model (black line) closely matches any given credit spread (red line). The blue lines represent the 10% and 90% quantiles of the simulated credit spreads.
Financial Stochastic Models Diffusion: From Risk-Neutral to Real-World Measure
Abstract: This research presents a comprehensive framework for transitioning financial diffusion models from the risk-neutral (RN) measure to the real-world (RW) measure, leveraging results from probability theory, specifically Girsanov's theorem. The RN measure, fundamental in derivative pricing, is contrasted with the RW measure, which incorporates risk premiums and better reflects actual market behavior and investor preferences, making it crucial for risk management. We address the challenges of incorporating real-world dynamics into financial models, such as accounting for market premiums, producing realistic term structures of market indicators, and fitting any arbitrarily given market curve. Our framework is designed to be general, applicable to a variety of diffusion models, including those with non-additive noise such as the CIR++ model. Through case studies involving Goldman Sachs' 2024 global credit outlook forecasts and the European Banking Authority (EBA) 2023 stress tests, we validate the robustness, practical relevance and applicability of our methodology. This work contributes to the literature by providing a versatile tool for better risk measures and enhancing the realism of financial models under the RW measure. Our model's versatility extends to stress testing and scenario analysis, providing practitioners with a powerful tool to evaluate various what-if scenarios and make well-informed decisions, particularly in pricing and risk management strategies.
Mohamed Ben Alaya, Ahmed Kebaier, Djibril Sarr, 2024. (Preprint available here.)
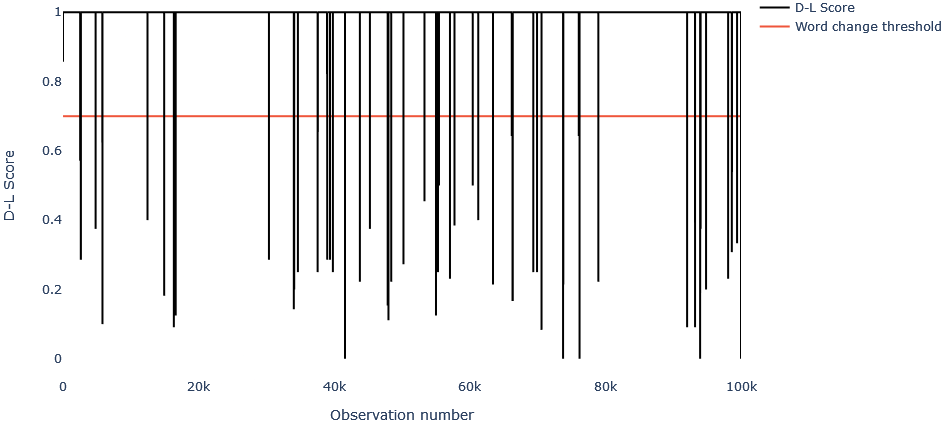
This figure shows a step in our typo detection algorithm. High Damerau-Levenshtein scores (black line) indicate word variations; drops below the threshold (red line) suggest different words.
Towards Explainable Automated Data Quality Enhancement without Domain Knowledge
Abstract: In the era of big data, ensuring the quality of datasets has become increasingly crucial across various domains. We propose a comprehensive framework designed to automatically assess and rectify data quality issues in any given dataset, regardless of its specific content, focusing on both textual and numerical data. Our primary objective is to address three fundamental types of defects: absence, redundancy, and incoherence. At the heart of our approach lies a rigorous demand for both explainability and interpretability, ensuring that the rationale behind the identification and correction of data anomalies is transparent and understandable. To achieve this, we adopt a hybrid approach that integrates statistical methods with machine learning algorithms. Indeed, by leveraging statistical techniques alongside machine learning, we strike a balance between accuracy and explainability, enabling users to trust and comprehend the assessment process. Acknowledging the challenges associated with automating the data quality assessment process, particularly in terms of time efficiency and accuracy, we adopt a pragmatic strategy, employing resource-intensive algorithms only when necessary, while favoring simpler, more efficient solutions whenever possible. Through a practical analysis conducted on a publicly provided dataset, we illustrate the challenges that arise when trying to enhance data quality while keeping explainability. We demonstrate the effectiveness of our approach in detecting and rectifying missing values, duplicates and typographical errors as well as the challenges remaining to be addressed to achieve similar accuracy on statistical outliers and logic errors under the constraints set in our work.
Djibril Sarr, 2024. (Preprint available here. This work is substantially founded on the work presented at the 2021 Mathematics and Industry Challenge of AMIES, Agence pour les Mathématiques en Interaction avec l’Entreprise et la Société. This work was awarded the first prize in the data quality competition.)
Teaching
Machine Learning for Finance
Institution: Master 2 Quantitative Finance, Université Paris Saclay (Since 2022-2023)
In this course, I introduce students to the field of machine learning (ML) and deep learning (DL) applied to finance.
The curriculum begins by reinforcing fundamental ML/DL concepts such as logistic regressions and feedforward neural networks.
The lectures then proceed with practical applications aimed at solving real-world problems, using Python and R. Key areas include:
- Algorithmic Trading: Exploring simple strategies for algorithmic trading using ML.
- Macroeconomic Indicator Clustering: Utilizing unsupervised learning techniques to cluster macroeconomic indicators for better selection of factors in multifactorial credit risk modeling.
- Deep Calibration of Financial Models: Applying DL techniques to improve calibration accuracy and computational cost for financial models.
Students leave the course equipped with essential knowledge and practical experience to apply ML and DL tools in various sectors of finance, most importantly, with knowledge of how to generalize the techniques seen in class to the problems they will encounter in their careers.
Cutting Edge Finance
Institution: Master 2 Quantitative Finance, Université Paris Saclay (Since 2022-2023)
This project-based course challenges students to solve real-world quantitative finance problems using advanced methodologies. As a tutor, I guide students through complex issues, providing guidance throughout the second semester.
- 2022-2023: Acceleration of Multi-Level Monte Carlo simulations through the integration of neural networks.
- 2023-2024: Calibration of countercyclical factors for counterparty credit risk models.
Students develop problem-solving skills, teamwork abilities, and gain exposure to innovative finance techniques used in professional settings.
Data Camp
Institution: Master 2 Data Science, Université Paris Saclay (2021-2022)
As a tutor, I supervised and mentored students participating in global Kaggle competitions. The objective was to expose students to competitive data science projects, emphasizing critical thinking, practical implementation, and teamwork. Key projects included:
- G-Research Crypto Forecasting: Students developed predictive models for cryptocurrency prices, working with complex time series data and financial indicators.
- APTOS 2019 Blindness Detection: In this project, students created computer vision models to classify retinal images and predict the severity of diabetic retinopathy.
